Activepieces workflow demoReady Paths · Workflow automation
31 Seconds. Zero GPU Setup. One Completed AI Job.
See a real AI workload run from an Activepieces workflow through Jungle Grid Ready Paths — from trigger to completed result in 31 seconds, without manually provisioning or selecting GPUs.
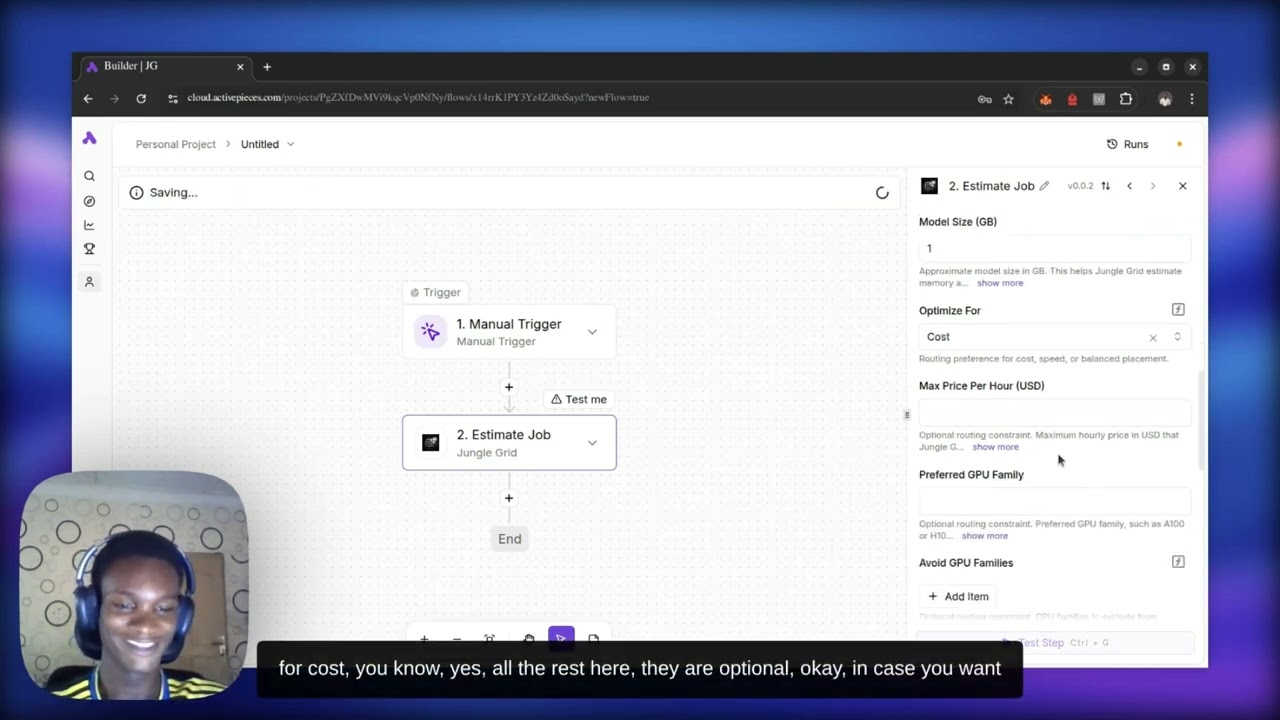
Shows: Activepieces workflow → Jungle Grid execution → completed workloadWatch on YouTube

